Okay, so let’s talk about being stuck, shall we? Or, rather, to start it on a positive note, about getting unstuck. Why do people end up in this situation in the first place? Well, there are probably heavy books about this topic, and I’m risking to sound too pretentious trying to figure it out in one paragraph, but anyway. I think that the principal reason here is the fear of new things, lack of exciting stuff and the rigid habits that keep us from progressing. It is safe to play the same set of exotic scales and independence exercises for months even though it gets incredibly boring. Weirdly enough, the fear of new might become so strong that it will make boredom look acceptable, even cozy. Which sucks, because now you have to turn everything upside down, mate. But I’ve been there, and I emerged on the other end. So, to wrap up this rather longish intro — how did I break from this trap? That’s right — I jumped head-on into the most dissonant, weird and scary routine: Exercises for Independence of the Fingers by Isidor Phillip.

It’s a monumental work that’s been very popular among classical pianists and, in fact, remains one of the most recommended books on the topic of finger independence, which it clearly states in the title. It is also one of the most crazy, dissonant, finger-cribbling, brain-melting, thought-freezing, torpor-inducing, I-suck-so-much-attitude-provoking source of piano exercises I have ever used in my life. Basically, what it does is it tells you to set your hands in a fucked up position and then make sure your every single finger is being fucked up in an equal measure. And, as if this were not enough, it tells you to transpose the whole thing in all 12 keys. So, as you can see, it sounds like a perfect solution for pretty much any desperate plateau situation.
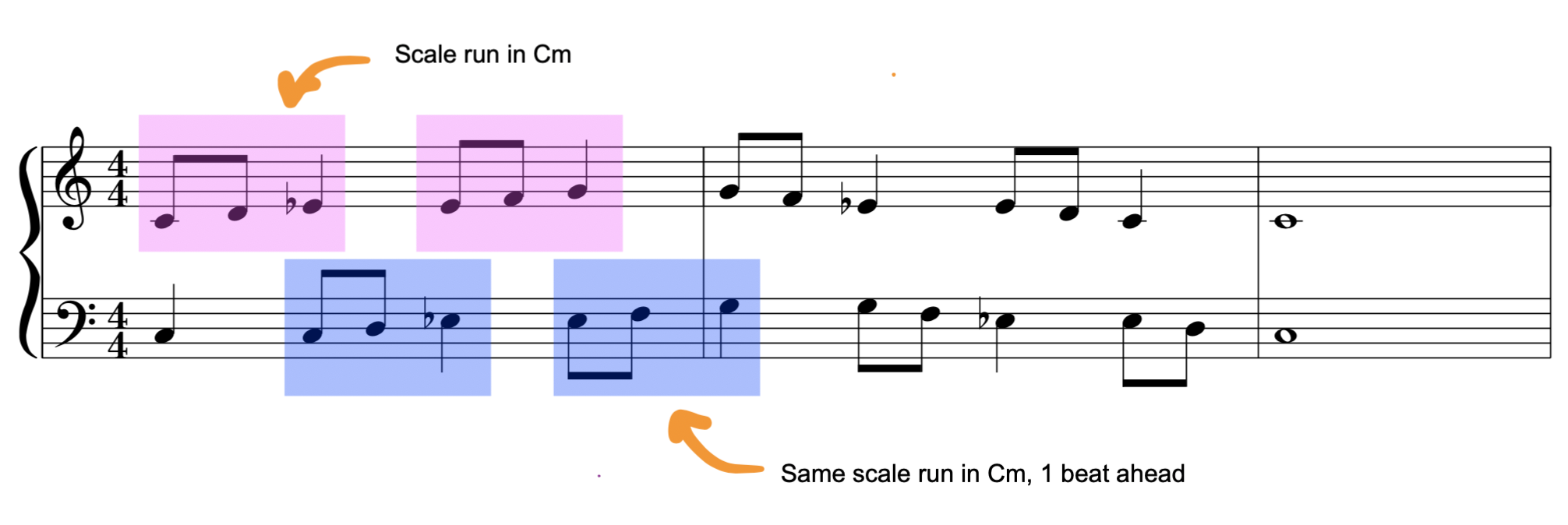
I started on the first page. It took me several days to master this finger-twister in several keys. In fact, it’s a pretty pleasant-sounding exercise, take a listen:

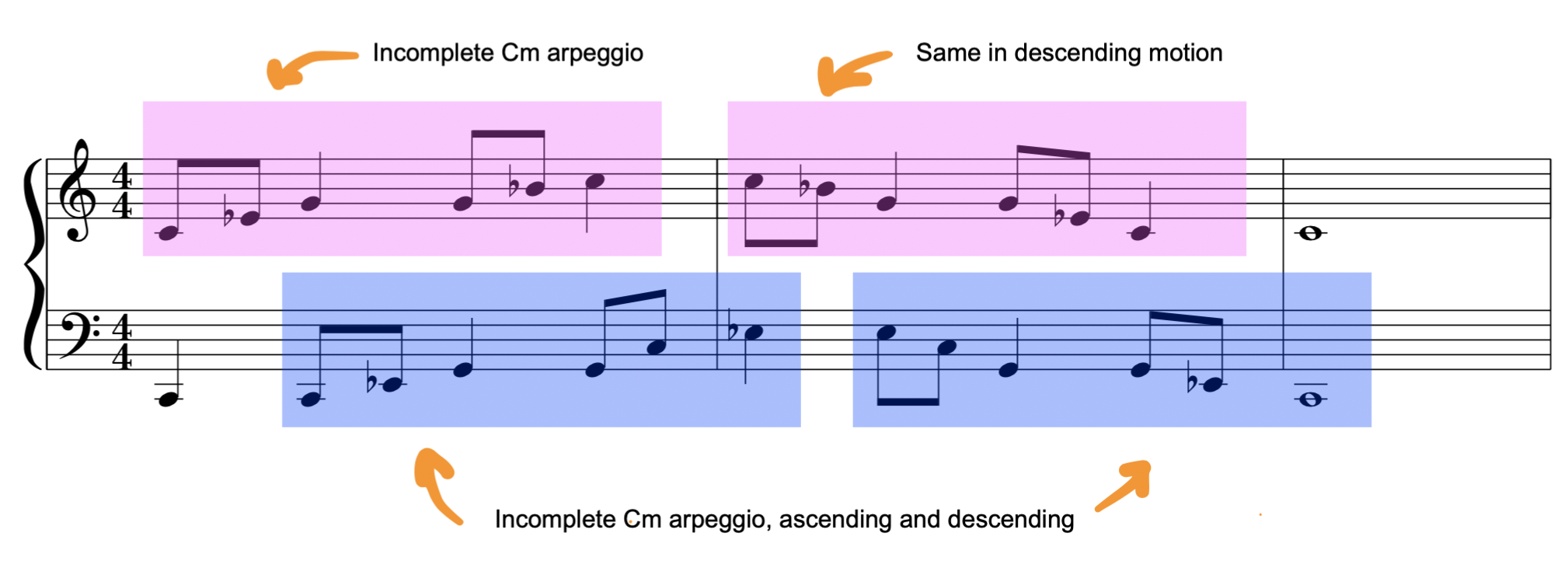
Then, of course, I skipped to the middle of the second book (classic) and embarked on this one:
That was terrible. It sounded nothing like music and was unbearably hard to play in fast tempos. But I got through it! And guess what? Because of its insane complexity, it required my entire processing power to focus on it, so I ended up having to move my mouse cursor as my laptop screen went dark as I was familiarising with the pattern. I was finally doing the Work! The feeling of getting off the plateau gave me a huge boost of confidence and I jumped right to the second part of the book to attack this monster:

Yeah, baby. It was fun to learn. I remember spending an entire hour of my 3-hour routine just learning this incredibly fucked up pattern. And I got this one nailed too! Check out how awful it sounds:
Want a joke? They are, in fact, just two parts of one mega-pattern that is supposed to be played with two hands simultaneously! Yes, you can do it. I decided not to record as it would probably have taken me ages to get a clean take 🙈
Have you noticed the amount of occurrences of the phrase “fucked up” in this text? I guess I might have surpassed my normal threshold, and that’s not without a reason. In fact, upon closer analysis of this exercise I realised that Mr. Philipp apparently did that with of good intention, and not at all to make my brain melt. He made me play all those diminished chords because he cared about my finger dexterity and he didn’t want me to do the stretching exercises while I’m focusing on independence skills. But what if he didn’t give a fuck? What if he went all berserk? I can do anything in the name of musicality, dude! Stretch over a major 10th in order to get something that sound a ted more musical? Hell yeah!
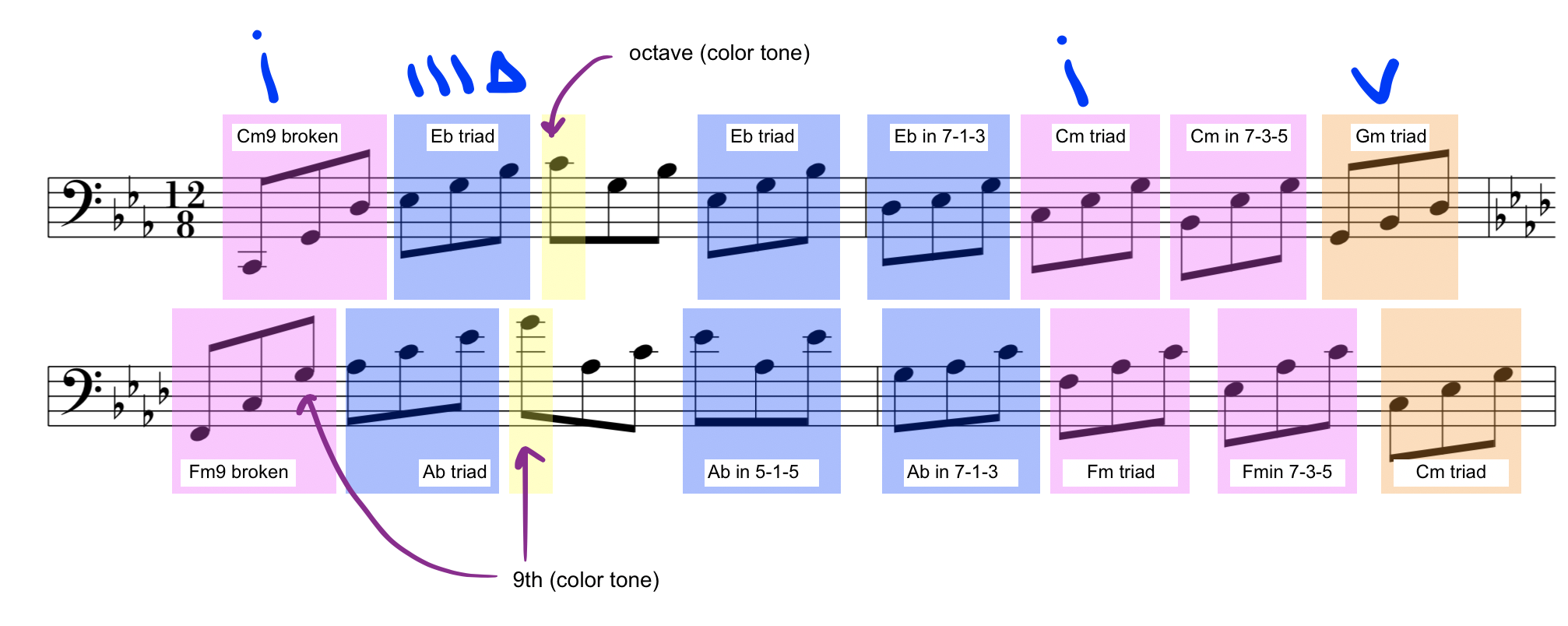
So I did that. Or, to be precise, I undid — all the diminishing, all the flattening, all that was supposed to accommodate my poor fingers. And look, mom, what come out of it!
Isn’t it amazing? This is the same pattern, but with all minor and diminished intervals replaced with their natural versions. Here’s the left hand:

Here’s the right:

And both hands together:

Doesn’t it sound almost like a new age minimalist piece? It sure does! Therefore, I decided to call this rendition of the classic exercise the “New Age Philipp”. Of course, we can develop it further and conceive a left hand figure that might be very useful in improvisation. And — remember all those patterns I’ve been talking since forever in this blog? Well, you can just incorporate them here and make this exercise sound even less like an exercise!
I remember watching a video on YouTube with a classical pianist explaining how Philipp’s books are purely technical, absolutely non-musical and how you should think about them only as a workout for your fingers. But guess what? Seems like you just need to tweak a tool a bit, and it will become the source of inspiration.
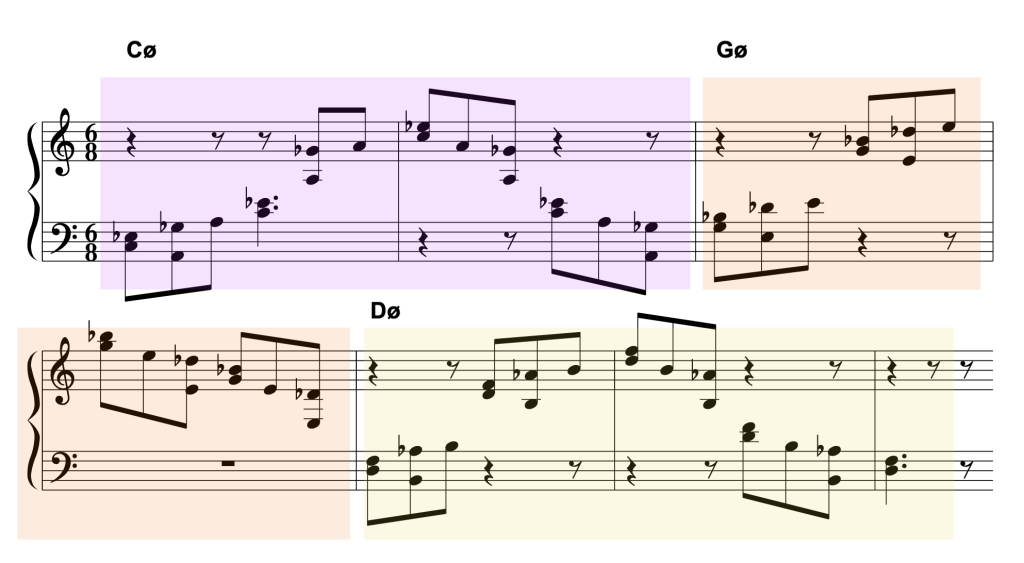
And, to conclude this post, a little piece makes use of the above patterns — both in left and right hands:
By the way, if you are by chance in listening to some longer pieces that I record, feel free to check my Spotify page or my SoundCloud stream, or just google me and check out my releases on all the streaming platforms in all possible universes. I do them — releases, not universes (unless you’re a quantum physicist on the free ride through the Web) — I do them pretty often, and it’s not just piano. But that’a topic for another plug!
Voilà, I hope this was helpful for you guys and that you have learned something! If you don’t have these books, definitely go buy them, they are awesome, and, by all means — harmonise till it hurts! (Metaphorically, not proverbially, keep your fingers safe.)